|
AIRAC (RAISEF)
|
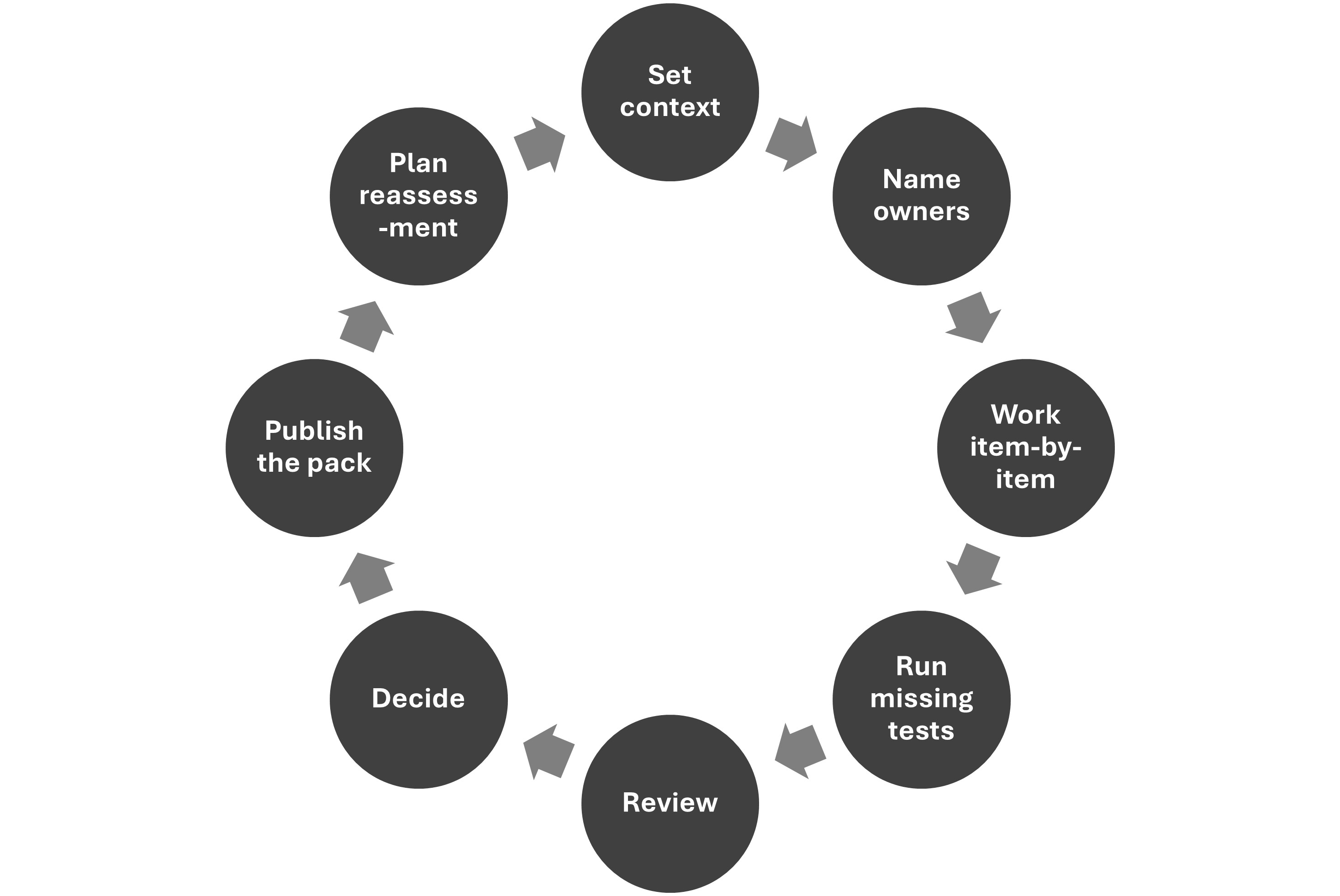
Full lifecycle (Sections 1–10): scope → mapping → harms → risk catalog → criteria → evaluation → prioritization → controls → decision → ops/assurance.
|
Explicit items: prompts, RAG freshness/citations, hallucination/factuality, injection/jailbreak, watermark/provenance, safety layering.
|
L1–L4 (Self-attest → Peer-review → Independent internal → Independent external) with explicit "check-when" criteria.
|
Named R/A sign-offs; section approvals; conditional acceptance needs owner, ticket, expiry, fallback.
|
Live monitoring metrics, incident playbook, re-assessment cadence; canarying/rollback patterns.
|
CC BY-NC 4.0 (free non-commercial use with attribution).
|
You need an auditable, item-by-item review with clear gates for classic ML or GenAI.
|
RAISEF AIRAC
|
|
NIST AI RMF Playbook
|
Framework functions (Govern, Map, Measure, Manage); broad guidance and activities rather than a single checklist.
|
Generative AI Profile available; risk actions tailored to GenAI use cases.
|
No fixed L1–L4 scheme; emphasizes documentation, measurement, and organizational processes.
|
Govern function stresses roles, policies, and accountability structures.
|
Manage function covers monitoring, incident response, and continuous improvement.
|
Free public guidance.
|
You want a reference framework to inform policies and risk programs across the org.
|
NIST AI RMF
|
|
Canada TBS Algorithmic Impact Assessment (AIA)
|
Questionnaire assessing impact level for automated decision systems used by federal institutions.
|
Not GenAI-specific; applicable to a range of ADS use cases.
|
Self-assessment questionnaire; produces required mitigation measures by impact level.
|
Mandated governance controls and public transparency for higher impact levels.
|
Requires impact-appropriate measures (e.g., human review, monitoring, notice).
|
Free; required for Government of Canada departments.
|
You need a formal impact level and mandated controls in the public sector.
|
TBS AIA
|
|
UK ICO AI & Data Protection Risk Toolkit
|
Spreadsheet/toolkit to identify and treat data-protection risks in AI systems.
|
Not GenAI-specific; applies data-protection principles to any AI.
|
Evidence captured via risk/action logs; no L1–L4 scheme.
|
Focus on controller/processor responsibilities and DPIA integration.
|
Practical actions for monitoring and review under UK GDPR.
|
Free; maintained by the regulator.
|
You are prioritizing data-protection compliance and DPIA alignment.
|
ICO Toolkit
|
| Singapore IMDA AI Verify |
Testing framework and tool for validating claims (e.g., fairness, robustness, transparency) with a conformance report.
|
Actively adds GenAI tests and guidance; scenario-based evaluations.
|
Evidence is test-artifacts and reports; no L1–L4; emphasizes measurable test results.
|
Governance captured through documentation and tester declarations.
|
Operational test suites; integrates with technical evaluations.
|
Free to try; programmatic engagement with IMDA.
|
You want a test-oriented approach that produces a technical conformance report.
|
AI Verify
|
|
ISO/IEC 42001 (AI Management System)
|
Organization-level management system standard for AI; policies, processes, and continual improvement.
|
Technology-agnostic; applicable to GenAI via risk/controls integration.
|
Audit-based conformity assessment; no itemized L1–L4 model.
|
Strong emphasis on roles, accountability, and documented procedures.
|
Requires operational monitoring and improvement cycles.
|
Paid standard; third-party certification available.
|
You need certifiable management-system assurance for customers/partners.
|
ISO/IEC 42001
|
|
EU AI Act (context)
|
Regulatory obligations by risk class; conformity assessment, technical documentation, post-market monitoring.
|
Includes provisions for general-purpose/GenAI models and systemic risks.
|
Evidence defined by legal requirements; notified-body assessment for certain systems.
|
Mandated governance, risk, and transparency measures.
|
Post-market monitoring & incident reporting required.
|
Law; official journal publication.
|
You sell or deploy in the EU and need legal compliance mapping.
|
EU AI Act
|
 RAISEF
RAISEF